

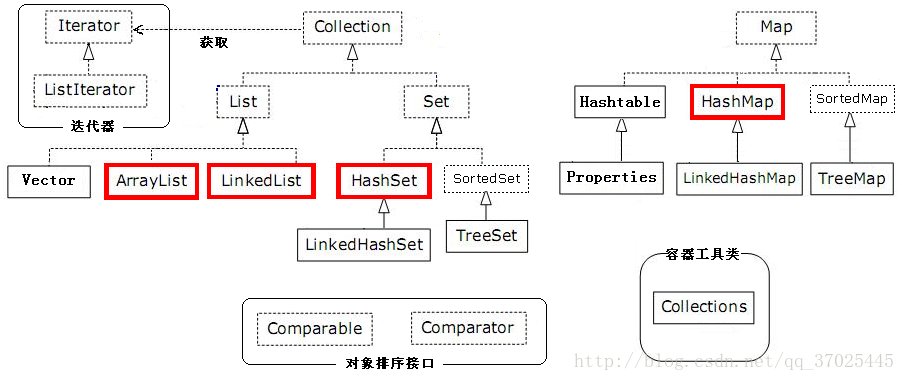
在Java中集合分为单列集合(Collection)与双列集合(Map),本文主要对两种集合的常用实现类作一介绍,如果有不足,恳请指教更正。
1.前言
说到集合肯定要介绍下集合的概念与特点:集合是一个容器,能够用来存储引用数据类型,长度是可变的。说到存储数据的容器大家脑海里想到的肯定还有数组,数组也是一个容器,可以用来存储任意类型的数据,但是长度是不可变的。因此数组有很大的局限性,在开发中存储数据我们一般都使用集合。
(图是拷贝的)
2.Collection单列集合
Collection是单列集合的顶层父接口,其下分为List集合与Set集合两大类。List集合与Set集合各有其特点:
List集合:1.元素存取有序 2.有索引 3.元素可以重复
Set集合:1.元素存取无序 2.无索引 3.元素不能重复
(元素存取有序是指按什么顺序存的就按什么顺序取出)
2.1List集合
List集合下常用的实现类有ArrayList、LinkedList、Vector。
2.1.1ArrayList
ArrayList集合在我们平时开发中使用的频率最高,其底层其实是Object数组,所以查询快,增删慢。为什么这么说呢?因为在数组结构中数组在内存中是连续的,数组的地址值其实是连续空间的第一个空间的地址,由于连续性,数组就可以通过直接计算出对应空间的地址值从而实现快速查询,但是数组长度不可变,如果我们要在数组中进行增删操作,需要创建一个新的数组,还要把原数组中的元素复制过去,这就导致了增删慢。
2.1.2LinkedList
LinkedList集合的底层是一个双向链表,所以查询慢,增删快。在这里要说明一下链表结构,链表结构其实是有多个节点连接起来,节点最少由数据部分、地址部分2部分组成。数据部分:存数据。地址部分:存下一个节点的地址。多个节点之间通过地址进行连接。例如:多个人手拉手,每个人使用自己的右手拉住下一个人的左手,一次类推,这样多个人就在一起了。这种数据接口查找慢的原因是:链表中的数据是离散的,没有任何规律,必须从第一个节点开始一个一个向后查询,而增删快的原因是:节点它可以记录下一个节点的地址值,链表中增删数据时,不用修改原本数据的内存地址值,增加元素只需要修改连接下个元素的地址即可,同理,删除元素也只需要修改下个元素的地址即可。
2.1.3Vector
Vector集合底层是扩展的对象数组,功能与ArrayList集合相似,但是Vector是线程安全的,而ArrayList是线程不安全的,线程安全带来的弊端就是效率比较低,所以Vector集合一般很少使用。
2.2单列集合的遍历
集合数据的添加可以通过集合中的add方法实现,那么要怎么获取集合中的元素呢?
集合中元素的获取可以通过一般for循环、增强(高级)for循环、迭代器实现,这里主要说一下高级for循环和迭代器。
高级for循环也叫foreach循环,是从JDK1.5之后出现的,专门用来遍历数组和集合。其使用格式为:for(数据类型 变量名 :容器){ 循环体 }。注意:数组的增强for循环底层是普通for循环;集合的增强for循环底层原理是迭代器。
迭代器(Iterator)可以简单的看作是一个具有光标(指针)的遍历集合的工具。是Collection集合元素的通用获取方式。一开始指向集合元素的第一个位置的值,在取元素之前先要判断集合中有没有元素,如果有,就把这个元素取出来,继续在判断,如果还有就再取出出来,一直把集合中的所有元素全部取出,这种取出方式专业术语称为迭代。有人可能会问有了这么简单的foreach循环为什么还要使用迭代器?
foreach循环遍历与迭代器遍历比较:
如果对集合中的元素随机访问,foreach循环中的get()方法采用的就是随机访问的形式,因此在ArrayList集合中,foreach遍历较快。
如果对集合中的元素顺序访问,迭代器中的next()方法,采用的就是顺序访问的形式,因此在LinkedList集合中,使用迭代器较快。
从数据结构角度分析,for循环适合访问顺序结构,可以根据下标快速获取指定元素.而Iterator 适合访问链式结构,因为迭代器是通过next()和Pre()来定位的.可以访问没有顺序的集合.大佬们都在玩{精选官网网址: www.vip333.Co }值得信任的品牌平台!
foreach只是让代码更加简洁了,但是他有一些缺点,就是遍历过程中不能操作数据集合(删除等),所以有些场合不使用,而迭代器可以在遍历过程中操作集合,但值得注意的是必须用迭代器对象操作集合,而不是集合对象操作集合!比如你要遍历一个集合,当满足某条件时候,删除一个元素, 如果用的是foreach循环,就用集合自带的remove(),而这样就改变了集合的Size()循环的时候会出错但如果把集合放入迭代器,既iterator迭代可以遍历并选择集合中的每个对象而不改变集合的结构,而把集合放入迭代器,用迭代器的remove()就不会出现问题。
迭代器遍历过程:
1.有一个单列集合对象
2.调用集合对象的iterator获取迭代器
3.调用迭代器的hasNext方法判断是否还有数据
4.如果有调用迭代器的next方法来获取
2.2 Set集合
Set集合下常用的实现类有HashSet、LinkedHashSet、TreeSet。
2.2.1 HashSet
HashSet集合的底层是哈希表,哈希表在JDK1.8之后新增了红黑树,即哈希表=数组+链表+红黑树。当向哈希表中存储数据时,先判断哈希值(hashcode),再判断内容(equals),这也是哈希表的去重方式。哈希表的存储方式是数组存放的是哈希值不同的元素,链表是用来存放哈希值相同但内容不同的元素,当链表的长度超过8时会自动变成红黑树,提高效率。 在向HashSet集合中存储自定义对象时,一定要重写hashcode()和equals()方法,以实现对自定义对象的去重。
(哈希值:是一个十进制的int值,它表示一个对象的特征码(可能相同),重写后是以对象的属性值按照一定的计算方式获取的,所以如果属性内容相同,2个不同地址值的对象的哈希值有可能一样。)
扩展:在哈希表中地址不同的2个对象,内容相同,哈希值是可能一样的;地址不同,内容也不同,哈希值也有可能一样。
2.2.2 LinkedHashSet
LinkedHashSet集合的底层是双向链表+哈希表,而链表是用来保存顺序的,所以LinkedHashSet就实现了存取有序了,是Set集合中唯一一个能保证怎么存怎么取的集合。LinkedHashSet集合同样有去重的作用,不能存储重复数据,其功能除了有序外,与HashSet集合差不多。
2.2.3 TreeSet
TreeSet底层是二叉树结构, 实现了SortedSet接口 ,能够对集合中对象进行排序(升序),同样具有去重,不重复的特点。
针对自定义对象的排序可以分为两种方式:
方式1:实现Comparable接口,实现compareTo方法,这种方式也称为元素的自然排序。口诀:我减它>0是升序
方式2:Comparator比较器,这种方式常用于匿名内部类,不用修改源码,所以比较常用。口诀:我减它>0是升序
(使用比较器就不用实现Comparable接口了)
3 Map集合
Map 集合是双列集合的顶层父接口,该集合中每个元素都是键值对<key,value>,成对出现。双列集合中,一个键一定只找到对应的一个值,键不能重复,但是值可以重复。
Map集合常用的实现类有HashMap、LinkedHashMap、HashTable,TreeMap。
3.1 HashMap
HashMap的底层是哈希表,与HashSet相似,只是数据的存储形式不同,HashMap可以使用null作为key或value,是线程不安全的,但是效率相对较高。当给HashMap中存放自定义对象时,如果自定义对象作为key存在,这时要保证对象唯一,必须复写对象的hashCode和equals方法。
3.2 HashTable大佬们都在玩{精选官网网址: www.vip333.Co }值得信任的品牌平台!
HashTable与HashMap之间的关系完全类似于Vector和Arraylist的关系。HashTable是线程安全的,但是效率相对较低,Hashtable不允许使用null作为key和value。
3.3 LinkedHashMap
LinkedHashMap是HashMap的子类,其底层是链表+哈希表结构,其关系与HashSet和LinkedHashSet类似,使用链表来维护key-value的次序,可以记住键值对的插入顺序。
3.4 TreeMap
TreeMap存储key-value键值对时,需要根据key对节点进行排序。TreeMap可以保证所有的key-value对处于有序状态。也有两种排序方式:
1) 自然排序:TreeMap的所有key必须实现Comparable接口,而且所有的key应该是同一个类的对象,否则抛出ClassCastException异常。大佬们都在玩{精选官网网址: www.vip333.Co }值得信任的品牌平台!
2) 定制排序:创建TreeMap时,传入一个Comparator对象,该对象负责对TreeMap中的所有key进行排序。不需要Map的key实现Comparable接口。
Map集合的遍历:
map集合采用put(key,value)的形式保存键值对数据,对于双列集合Map中键值对形式的数据如何遍历呢?
Map接口是没有Iterator方法,所以不能直接获取迭代器进行遍历;双列集合没有实现Iterable接口,因此也不能直接通过增强for(foreach)循环遍历。
因此我们只能间接的对Map集合进行遍历,方式有2种。
第一种:键找值方式
1.调用keySet()方法获取到双列集合的所有key,存放到set单列集合中
2.迭代器遍历或者增强for循环遍历单列set集合中的key,通过双列集合的get(key)方法获取value
第二种:键值对方式
1.调用entrySet()方法获取到双列集合的所有键值对对象,存放到set集合中
2.迭代器遍历或者增强for循环遍历单列set集合获取到键值对对象,通过getKey()和getValue()方法获得键和值。


文章声明:以上内容(如有图片或视频在内)除非注明,否则均为直播吧 - 欧洲杯直播_CCTV-5在线直播|NBA直播原创文章,转载或复制请以超链接形式并注明出处。
本文作者:admin本文链接:https://iztgb.com/post/414.html



